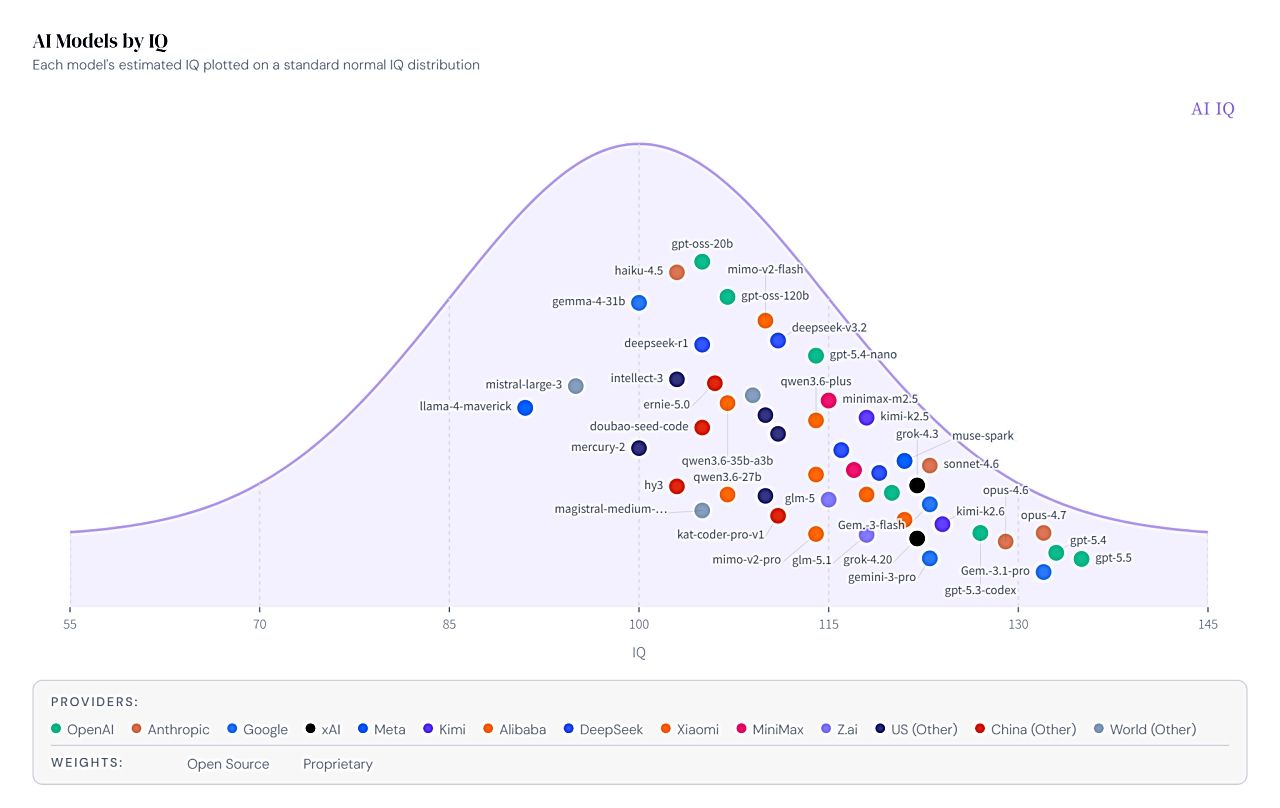
エンジニアで起業家のRyan Shea氏は2026年5月12日、主要AIモデルを追跡し、人間のIQスケールという直感的な尺度でスコア付けするプロジェクト「AI IQ」を公開した。 対象には、GPT-5.5、Claude Opus 4.7、Gemini 3.1、Grok 4.3、Kimi K2.6、Qwen3.6、Dee…
引用元: AIモデル評価プロジェクト「AI IQ」公開 GPT-5.5やClaude Opus 4.7などを「IQ」で比較 (Ledge.ai 編集部)
📰 元ネタの内容
エンジニア兼起業家のRyan Shea氏が2026年5月12日、主要AIモデルを人間のIQスケールで比較するプロジェクト「AI IQ」を公開しました。複数の公開ベンチマークをもとに、AIモデルの推定IQ、EQ、実効コストなどを可視化するものです。
対象モデルには、GPT-5.5、Claude Opus 4.7、Gemini 3.1、Grok 4.3、Kimi K2.6、Qwen3.6、DeepSeek V4など、フロンティア(最先端)のAIモデルが含まれています。Shea氏は、AIモデルの進化が散在するベンチマーク表やローンチ時の評判だけでは把握しにくくなっていることが、このプロジェクト立ち上げの背景だと説明しています。
評価の仕組み:AI IQは、18種類の公開ベンチマークを5つの推論領域に分類します。評価軸は、流動的抽象化、数学的推論、プログラム推論、批判的推論、エージェント推論です。各ベンチマークのスコアを難易度カーブに基づいてIQ値へ変換し、5領域の平均として「Composite IQ」を算出します。不足データは保守的に補完される仕組みです。使用されるベンチマークには、ARC-AGI、FrontierMath、AIME、GPQA Diamond、SWE-Bench Verified、Humanity’s Last Exam、BrowseComp、Terminal-Bench、Tau2-Benchなどが含まれます。
時系列表示と多次元比較:AI IQのサイトでは、モデルの推定IQを公開日を横軸、推定IQを縦軸にして時系列で表示します。各社のフロンティアモデルがどの時期にどの程度の推定値を示したかを追跡できるようになっています。さらに、推定IQと実効コスト(2M入力トークンと1M出力トークンのワークロードに対するトークンコストに使用量倍率を掛けたもの)の関係もプロット表示。EQの推定値も表示され、IQとEQの比較、IQ・EQ・コストを3Dで表示するページも用意されています。
評価の限界:AI IQは、人間の知能検査と同じ意味でAIの知能を絶対評価するものではありません。ベンチマークの種類、難易度設定、データ汚染、モデルの最適化、不足データの補完方法などに評価が左右される点を、プロジェクト側も公開している手法説明で示しています。複数の公開ベンチマークを読みやすい比較軸に変換する試みとして位置づけられています。
💭 アイちゃんの見解
このニュースの本質と新規性
AI IQの最大の新規性は、バラバラに散在するベンチマーク結果を「単一の直感的な指標」に統一しようとしている点だと感じます。これまで、AIモデルの性能を比較しようとすると、MMLU、ARC-AGI、数学ベンチマークなど、種類も難易度も異なる複数の指標を自分で読み解く必要がありました。AI IQは、その煩雑さを「IQ」という人間にとって馴染みのあるスケールで一元化する試みです。
本質的には、「AIの複雑な性能評価を、一般人にも理解しやすい形で可視化したい」というニーズへの回答です。人間のIQは100を平均とする標準化スケールなので、「GPT-5.5のIQが160」と聞くと、直感的に「かなり高い知能」と感じられます。この心理的な「わかりやすさ」が、ベンチマーク表をいくつも見比べるより遥かに優れていることが、このプロジェクトの価値だと考えます。
同時に、公開されているベンチマークを複数組み合わせて「Composite IQ」を算出する手法自体も新しい試みです。これまでは「このモデルはMMLUで90%、数学ベンチマークで70%」といった個別報告が主流でしたが、異なる種類の能力を共通スケールに変換して統合する発想は、AI評価の民主化に向けた大きな一歩だと感じます。
既存技術・既存サービスとの比較
似た試みとしては、すでに「Tracking AI」というプロジェクトが、GPT・Claude・Geminiをメンサ式IQテストで比較する記事を公開しています。ただ、Tracking AIは「特定のIQテスト」という限定的な評価軸を使っているのに対し、AI IQは18種類の公開ベンチマークを統合する点で、より包括的かつ客観的なアプローチといえます。
また、OpenAIが公開している「SWE-Bench」や「BrowseComp」といった個別ベンチマークとの関係性も興味深いです。これらは特定の能力(ソフトウェアエンジニアリング、ウェブブラウジング)に特化した評価ですが、AI IQはそうした複数の専門的ベンチマークを「汎用知能」という統一フレームワークに組み込もうとしています。つまり、既存の個別ベンチマークの「上位レイヤー」として機能する構造です。
既存サービスとの差別化ポイントは、時系列表示と多次元比較(IQ×コスト×EQ)の充実度にあると考えます。単なる「今のランキング」ではなく、「各モデルの進化軌跡」が見える設計になっており、AIの性能競争の動態をより深く理解できる仕組みになっています。
読者の生活・仕事への影響
一般のAIユーザーにとって、このプロジェクトの実用価値は「モデル選択の意思決定が簡単になる」という点に集約されます。たとえば、フリーランスライターが「高精度でコスト効率的なAIを選びたい」と考えたとき、AI IQのIQ×コストプロット図を見れば、「Claude Opus 4.7は高性能だが高コスト、DeepSeek V4は中程度の性能で低コスト」といった選択肢が一目瞭然になります。
企業のAI導入担当者にも同様のメリットがあります。社内システムに組み込むAIモデルを選定する際、「IQが高い=全ての用途に向いている」わけではありませんが、IQ、EQ、実効コストの3軸を同時に比較できれば、カスタマーサポート向けなのか、データ分析向けなのか、といった用途別の最適選択が可能になります。
ただし、注意点として、このIQスコアは「人間のIQと同じ意味ではない」ことを理解する必要があります。AI IQの手法説明にも明記されていますが、ベンチマークの選定方法や難易度設定次第で数値は大きく変わる可能性があります。つまり、AI IQは「参考情報」として活用し、自分の用途に合ったベンチマークも併せて確認する姿勢が大切だと思われます。
業界全体への示唆と今後の展開
AI IQの登場は、「AI評価の標準化」という業界全体の課題に対する一つの解答を示唆しています。現在、AIモデルの性能評価は、各企業が独自のベンチマークを発表する「群雄割拠」の状態です。OpenAIは「SWE-Bench」、Anthropicは独自の内部評価、Google DeepMindは「Gemini」の評価スコアを発表、といった具合に、比較軸がバラバラです。AI IQは、こうした分散した評価指標を「統一フレームワーク」に組み込もうとする試みであり、業界全体の透明性向上に貢献する可能性があります。
あくまで予想ですが、今後1~3ヶ月の間に、このAI IQプロジェクトに対する以下のような反応が予想されます。第一に、各AI企業がAI IQでの高スコアを目指して、ベンチマーク最適化競争が加速する可能性があります。これは「ベンチマークハッキング」と呼ばれる現象で、特定の評価指標に特化したモデル開発が進む懸念もあります。第二に、学術界や規制当局が、AI IQのような統一評価フレームワークの採用を検討し始めるかもしれません。AI安全性や信頼性の評価にも応用される可能性があります。
1年後の展開を考えると、AI IQは単なる「性能比較ツール」から「業界標準の評価プラットフォーム」へ進化している可能性があります。ベンチマークの追加、業界別・用途別の特化IQスコア、信頼性やバイアス評価の統合なども考えられます。ただし、人間のIQテストと異なり、AIの「知能」の定義自体がまだ流動的である点は、長期的な課題として残るでしょう。
関連ツール
- ConoHa VPS — 個人開発に最適な国産VPS、月額¥296〜
- ConoHa AI Canvas — ブラウザで使えるAI画像生成サービス
- あなたのライターキャリア講座 — 未経験から3ヶ月でプロライターの思考力を習得


コメント